Java集合框架
一、集合大纲
1、集合的继承结构
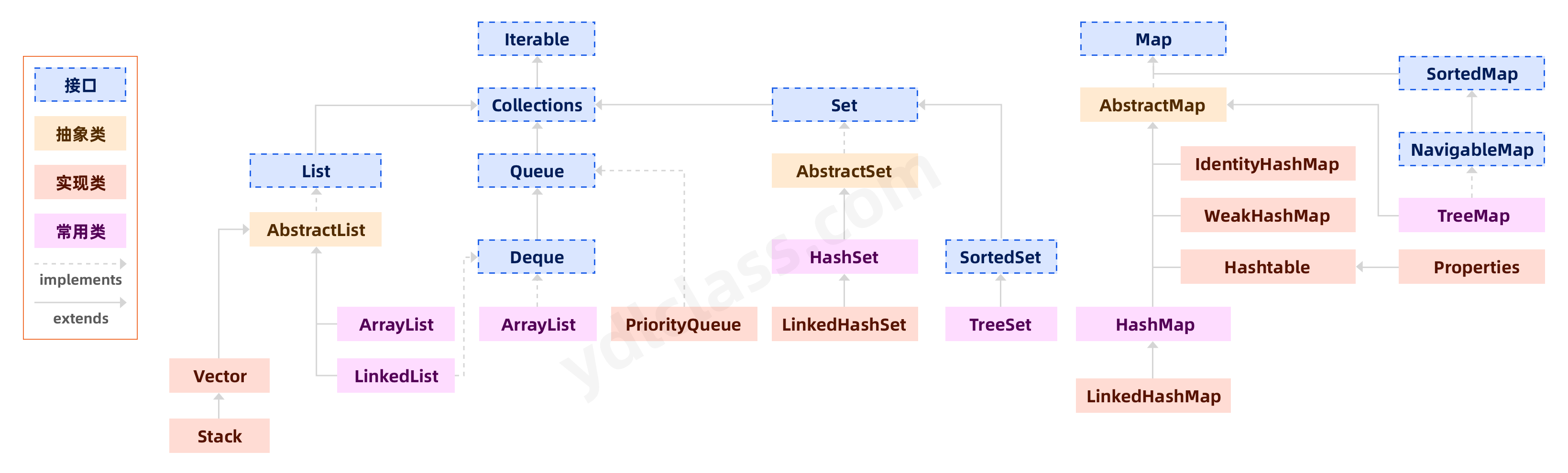 其实有了我们的超级数组的实战之后,我们学习集合将会很容易,java 的集合框架就是给我们提供了一套更加方便的存储数据的类而已。
其实有了我们的超级数组的实战之后,我们学习集合将会很容易,java 的集合框架就是给我们提供了一套更加方便的存储数据的类而已。
集合的目的是方便的存储和操作数据,其实说到底无非就是增删改查。
2、常用接口介绍
List( 列表)线性表:
- 和数组类似,List 可以动态增长,查找元素效率高,插入删除元素效率低,因为会引起其他元素位置改变。
Set(表)也是线性表
- 检索元素效率低下,删除和插入效率高,插入和删除不会引起元素位置改变。
Map(映射)
- Map(映射)用于保存具有映射关系的数据,Map 里保存着两组数据:key 和 value,它们都可以是任何引用类型的数据,但 key 不能重复。所以通过指定的 key 就可以取出对应的 value。
- List,Set 都是继承自 Collection 接口,Map 则不是
二、集合的增删改查
思考,其实我们能从几个接口源码中看明白集合到底是怎么进行增删改查的。
public interface List<E> extends Collection<E> {
int size();
boolean isEmpty();
boolean contains(Object o);
Iterator<E> iterator();
<T> T[] toArray(T[] a);
boolean add(E e);
boolean remove(Object o);
boolean containsAll(Collection<?> c);
boolean addAll(Collection<? extends E> c);
boolean addAll(int index, Collection<? extends E> c);
boolean removeAll(Collection<?> c);
void clear();
E get(int index);
E set(int index, E element);
void add(int index, E element);
E remove(int index);
}
// 你会发现set天然没有修改的方法
public interface Set<E> extends Collection<E> {
int size();
boolean isEmpty();
boolean contains(Object o);
Iterator<E> iterator();
Object[] toArray();
<T> T[] toArray(T[] a);
boolean add(E e);
boolean remove(Object o);
boolean containsAll(Collection<?> c);
boolean addAll(Collection<? extends E> c);
boolean removeAll(Collection<?> c);
void clear();
}
public interface Map<K,V> {
int size();
boolean isEmpty();
boolean containsKey(Object key);
boolean containsValue(Object value);
V get(Object key);
V put(K key, V value);
V remove(Object key);
void putAll(Map<? extends K, ? extends V> m);
void clear();
Set<K> keySet();
Collection<V> values();
Set<Map.Entry<K, V>> entrySet();
}
三、源码分析
本节知识比较难,大家量力而行,能学会多少是多少,特别是 hashmap。本节的内容可以现在学习,也可以以后学习。
第一次看源码,说说注意的问题:
- 一定要跟着我的节奏看。
- 一定要专注,需要上下文的结合阅读。
- 不要太扣细节,把源代码的整体思路阅读下来就行了。
- 有时间多读几次,慢慢脱离我的视频。
1、Arraylist
(1)成员变量
// 默认的空数组
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};
// 实际存数据的数组
transient Object[] elementData;
// 默认容量
private static final int DEFAULT_CAPACITY = 10;
(2)构造器
// 默认使用空数组
public ArrayList() {
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;
}
public ArrayList(int initialCapacity) {
if (initialCapacity > 0) {
this.elementData = new Object[initialCapacity];
} else if (initialCapacity == 0) {
this.elementData = EMPTY_ELEMENTDATA;
} else {
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
}
}
// ArrayList还可以直接传入一个集合
public ArrayList(Collection<? extends E> c) {
elementData = c.toArray();
if ((size = elementData.length) != 0) {
// 集合中有数据就拷贝数据
if (elementData.getClass() != Object[].class)
elementData = Arrays.copyOf(elementData, size, Object[].class);
} else {
// replace with empty array.
this.elementData = EMPTY_ELEMENTDATA;
}
}
(3)add 方法
public boolean add(E e) {
// 确保能不能放进去
ensureCapacityInternal(size + 1);
elementData[size++] = e;
return true;
}
private void ensureCapacityInternal(int minCapacity) {
ensureExplicitCapacity(calculateCapacity(elementData, minCapacity));
}
// 根据数组长度和传入的容量值计算容量
private static int calculateCapacity(Object[] elementData, int minCapacity) {
// 初始化时 就是空啊,他会选择10当他的容量值。
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
return Math.max(DEFAULT_CAPACITY, minCapacity);
}
return minCapacity;
}
private void ensureExplicitCapacity(int minCapacity) {、
// 记录了集合被修改的次数
modCount++;
if (minCapacity - elementData.length > 0)
grow(minCapacity);
}
// 数组扩容的地方
private void grow(int minCapacity) {
// 获取旧的容量
int oldCapacity = elementData.length;
// 很明显扩容了1.5倍
int newCapacity = oldCapacity + (oldCapacity >> 1);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// 扩容后拷贝数据
elementData = Arrays.copyOf(elementData, newCapacity);
}
(4)查找和删除
public E get(int index) {
rangeCheck(index);
return elementData(index);
}
E elementData(int index) {
return (E) elementData[index];
}
public E remove(int index) {
rangeCheck(index);
modCount++;
E oldValue = elementData(index);
int numMoved = size - index - 1;
if (numMoved > 0)
// System.arraycopy
// Object src : 原数组
// int srcPos : 从元数据的起始位置开始
// Object dest : 目标数组
// int destPos : 目标数组的开始起始位置
// int length : 要copy的数组的长度
System.arraycopy(elementData, index+1, elementData, index,
numMoved);
elementData[--size] = null;
return oldValue;
}
源码里能看到的信息:
1、arraylist 是基于数组实现的。
2、默认容量是 10,每次扩容是 1.5 倍的扩容(oldCapacity + (oldCapacity >> 1))。
2、linkedlist
(1)成员变量
transient int size = 0;
// 保存头结点
transient Node<E> first;
// 保存尾节点
transient Node<E> last;
// 节点的定义
private static class Node<E> {
E item;
Node<E> next;
Node<E> prev;
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
很明显,这里能够看出 linkedlist 是基于双向链表实现的。
(2)构造器
/**
* Constructs an empty list.
*/
public LinkedList() {
}
/**
* Constructs a list containing the elements of the specified
* collection, in the order they are returned by the collection's
* iterator.
*
* @param c the collection whose elements are to be placed into this list
* @throws NullPointerException if the specified collection is null
*/
public LinkedList(Collection<? extends E> c) {
this();
addAll(c);
}
(3)添加的方法
// 头上添加
private void linkFirst(E e) {
final Node<E> f = first;
final Node<E> newNode = new Node<>(null, e, f);
first = newNode;
if (f == null)
last = newNode;
else
f.prev = newNode;
size++;
modCount++;
}
// 尾巴上添加
void linkLast(E e) {
final Node<E> l = last;
final Node<E> newNode = new Node<>(l, e, null);
last = newNode;
if (l == null)
first = newNode;
else
l.next = newNode;
size++;
modCount++;
}
// 在某个元素之前添加
void linkBefore(E e, Node<E> succ) {
// assert succ != null;
final Node<E> pred = succ.prev;
final Node<E> newNode = new Node<>(pred, e, succ);
succ.prev = newNode;
if (pred == null)
first = newNode;
else
pred.next = newNode;
size++;
modCount++;
}
// 断开头部
private E unlinkFirst(Node<E> f) {
// assert f == first && f != null;
final E element = f.item;
final Node<E> next = f.next;
f.item = null;
f.next = null; // help GC
first = next;
if (next == null)
last = null;
else
next.prev = null;
size--;
modCount++;
return element;
}
// 断开尾巴
private E unlinkLast(Node<E> l) {
// assert l == last && l != null;
final E element = l.item;
final Node<E> prev = l.prev;
l.item = null;
l.prev = null; // help GC
last = prev;
if (prev == null)
first = null;
else
prev.next = null;
size--;
modCount++;
return element;
}
// 断开某一个节点
E unlink(Node<E> x) {
// assert x != null;
final E element = x.item;
final Node<E> next = x.next;
final Node<E> prev = x.prev;
if (prev == null) {
first = next;
} else {
prev.next = next;
x.prev = null;
}
if (next == null) {
last = prev;
} else {
next.prev = prev;
x.next = null;
}
x.item = null;
size--;
modCount++;
return element;
}
// 这两个方法中list接口中没有,是LinkedList类中特有的。
public void addFirst(E e) {
linkFirst(e);
}
public void addLast(E e) {
linkLast(e);
}
// 默认的添加是给尾巴添加
public boolean add(E e) {
linkLast(e);
return true;
}
(4)查找和删除
public E get(int index) {
checkElementIndex(index);
return node(index).item;
}
// 找到第几个node
Node<E> node(int index) {
// 看人家的检索,小于一半就从头检索,否则从尾巴检索
if (index < (size >> 1)) {
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}
// 获取头结点
public E getFirst() {
final Node<E> f = first;
if (f == null)
throw new NoSuchElementException();
return f.item;
}
// 获取尾节点
public E getLast() {
final Node<E> l = last;
if (l == null)
throw new NoSuchElementException();
return l.item;
}
// 删除默认删除头
public E remove() {
return removeFirst();
}
// 根据index删除
public E remove(int index) {
checkElementIndex(index);
return unlink(node(index));
}
// 这两个方法中list接口中没有,是LinkedList类中特有的。
public E removeFirst() {
final Node<E> f = first;
if (f == null)
throw new NoSuchElementException();
return unlinkFirst(f);
}
public E removeLast() {
final Node<E> l = last;
if (l == null)
throw new NoSuchElementException();
return unlinkLast(l);
}
3、hashmap
(1)初步了解
hashmap 的实现是比较复杂的。

在读 map 源码之前,我们先看一张图,了解 hashmap 的存储结构:
简而言之是这样的(不太对,但是有个大概的了解):
第一步:hashmap 构造时(其实不是构造的时候)会创建一个长度为 16 数组,名字叫 table,也叫 hash 表;
第二步:hashmap 在插入数据的时候,首先根据 key 计算 hashcode,然后根据 hashcode 选择一个槽位。
假设 hashmap 使用取余的方式计算。(事实上,hashmap 不是)
我们都知道 hashcode 会返回一个 int 值,使用 int 值除以 16 取余就能得到一个 0~15 的数字,就能去定一个具体的槽位。
第三步:确定了具体的槽位之后,我们就会封装一个 node(节点),里边保存了 hash,key,value 等数据存入这个槽中。
第四步:当存入新的数据的时候,使用新的 hash 计算的槽位发现已经有了数据,这个现象叫做 hash 碰撞,会以链表的形式存储。
第五步:当链表的个数到达了 8 个,链表开始树化,变成一个红黑树。
通过这五个步骤,大家先有一个基本的了解,更多的细节我们下来看源码。
(2)成员变量的分析
// 默认容量
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
// 最大容量
static final int MAXIMUM_CAPACITY = 1 << 30;
// 默认的加载因子
static final float DEFAULT_LOAD_FACTOR = 0.75f;
// 默认的一个树化的一个阈值 (THRESHOLD 阈值)
static final int TREEIFY_THRESHOLD = 8;
// 非树化的一个阈值
static final int UNTREEIFY_THRESHOLD = 6;
// 树化的最小容量,能看到一些信息,树化除了链表长度,对容量也有要求
static final int MIN_TREEIFY_CAPACITY = 64;
// 存储数据的hash表,就是一个数组
transient Node<K,V>[] table;
// 真实的负载因子
final float loadFactor;
(3)构造
// 只是将默认的负载因子传递给了loadFactor
public HashMap() {
this.loadFactor = DEFAULT_LOAD_FACTOR; // all other fields defaulted
}
// 有传入的初始化容量
public HashMap(int initialCapacity) {
this(initialCapacity, DEFAULT_LOAD_FACTOR);
}
// 有传入的初始化容量和负载因子
public HashMap(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
// 计算新的负载因子和容量
this.loadFactor = loadFactor;
this.threshold = tableSizeFor(initialCapacity);
}
/**
* 返回一个值,大于等于传入的数字的一个2的次幂的数字,你传入15返回16,传入7返回8、
* 保证了容量是2的次幂。为了后来计算hash槽做准备
*/
static final int tableSizeFor(int cap) {
int n = cap - 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}
static final int tableSizeFor(int cap) {
// 00010000 11101001 10001001 10000101 -- > 00010000 11101001 10001001 10000100 283,740,549
// 看完了
int n = cap - 1;
// 00010000 11101001 10001001 10000101 n
// 00001000 01110100 11000100 11000010 右移1位,保障2位是1
// 00011000 11101101 11001101 11000111 n
n |= n >>> 1;
// 00011000 11101101 11001101 11000111 n
// 00000110 00111011 01110011 01110001 右移2位,保障4位是1
// 00011110 11111111 11111111 11110111 n
n |= n >>> 2;
// 00011110 11111111 11111111 11110111 n
// 00000001 11101111 11111111 11111111 右移4位,保障8位是1
// 00011111 11111111 11111111 11111111 n
n |= n >>> 4;
// 00011111 11111111 11111111 11111111 n
// 00000000 00011111 11111111 11111111 右移8位,保障16位是1
// 00011111 11111111 11111111 11111111 n
n |= n >>> 8;
// 00011111 11111111 11111111 11111111 n
// 00000000 00000000 00011111 11111111 右移8位,保障32位是1
// 00011111 11111111 11111111 11111111 n
n |= n >>> 16;
return n + 1;
}
在构造的整个过程当中,并没有初始化 hash 表 table。
(4)put 方法
这个方法是核心,也是我们所需要研究的。很多的问题都是在这个方法当中。
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
// 第一个关键点:key == null,说明我们的hashmap支持key为null
// 第二个关键点: (h = key.hashCode()) ^ (h >>> 16) ,这一点学完,学完putVal方法再看
// h 1010 0010 0001 1001 0010 1100 1010 1001
// h >>> 16 0000 0000 0000 0000 1010 0010 0001 1001 ( 0010 1100 1010 1001)
// 异或运算 1010 0010 0001 1001 1000 1110 1011 0000
// 目的: 让高16位和低16位同时参与计算,将来计算hash槽时更加均匀
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
// tab很明显就是hash表
Node<K,V>[] tab;
// 就是个引用(指针),
Node<K,V> p;
// 先不要管,n代表hash表的长度(tab)
int n, i;
// (tab = table) == null 将hash表赋值给tab,并且判断是不是null
// 或者长度等于0,我就要扩容,构造没有初始化
if ((tab = table) == null || (n = tab.length) == 0){
// 那就扩容,还兼任初始化的责任(16)
n = (tab = resize()).length;
}
// p == null,只不过有个给p赋值的过程
// p = tab[i = (n - 1) & hash]
// 其实 i是计算的槽位,你的数据往哪个格子里放
// (n - 1) & hash 这是真实的计算过程,n确定是一个2的n次幂(100..),hash是一个int值
// (n-1) 0000 0000 0000 0000 0000 0000 0000 1111
// (hash) 0010 0010 0010 0010 0000 0110 0000 1011
// (result) 0000 0000 0000 0000 0000 0000 0000 1011
// 与运算之后的结果就是0~15,正好计算了一个槽位
// 第一个思考的问题:为什么容量必须是2的次幂? 0...01...1
// 第二个思考的问题:为什么使用位移运算而不适用余运算?效率
// 找到槽位,并且槽位没有数据,就直接newnode放进去
if ((p = tab[i = (n - 1) & hash]) == null){
// 创建了一个node
tab[i] = newNode(hash, key, value, null);
} else {
// 只要进入else,说明这个槽位有数据了,就要搞链表了
//
Node<K,V> e;
// 键,泛型,当前插入数据的键
K k;
// 根据p = tab[i = (n - 1) & hash],知道p是放在槽位上的node
// p.hash == hash 说明发生了hash碰撞
// (k = p.key) == key || (key != null && key.equals(k)) 判断的是key重复了
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k)))){
// 覆盖
e = p;
// 判断是不是树形节点
} else if (p instanceof TreeNode){
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
// 否则就是链表的方式
} else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
// 这不就是链表吗?很明显这是尾插
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
// 树化
treeifyBin(tab, hash);
break;
}
// 判断链表中有没有key一样的,覆盖
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
(5)扩容的方法
final Node<K,V>[] resize() {
Node<K,V>[] oldTab = table;
// 旧的容量
int oldCap = (oldTab == null) ? 0 : oldTab.length;
// 旧的阈值
int oldThr = threshold;
int newCap, newThr = 0;
if (oldCap > 0) {
// 容量大于最大值就取最大值
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
// 这里体现了扩容的大小
// newCap = oldCap << 1 相当于2倍
} else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
// 阈值月扩容二倍
newThr = oldThr << 1; // double threshold
// 旧的阈值大于零
} else if (oldThr > 0){ // initial capacity was placed in threshold
// 旧的阈值 = 新的容量
newCap = oldThr;
// 否则就是初始化,因为 == 0
} else { // zero initial threshold signifies using defaults
// 否则新的容量就是默认的容量
newCap = DEFAULT_INITIAL_CAPACITY;
// 新的阈值就是 容量*负载因子
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
// 计算新的阈值,要么是相乘,要么Integer最大值
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
// 将计算好的阈值赋值给 threshold
threshold = newThr;
@SuppressWarnings({"rawtypes","unchecked"})
// 根据新的容量创建了新的hash表
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
table = newTab;
// 以下是重新拷贝的过程
if (oldTab != null) {
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
if ((e = oldTab[j]) != null) {
oldTab[j] = null;
if (e.next == null)
newTab[e.hash & (newCap - 1)] = e;
else if (e instanceof TreeNode)
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
else { // preserve order
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
do {
next = e.next;
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
}
(6)树化的部分代码
/**
* Replaces all linked nodes in bin at index for given hash unless
* table is too small, in which case resizes instead.
*/
final void treeifyBin(Node<K,V>[] tab, int hash) {
int n, index; Node<K,V> e;
if (tab == null || (n = tab.length) < MIN_TREEIFY_CAPACITY)
// 优先扩容
resize();
else if ((e = tab[index = (n - 1) & hash]) != null) {
TreeNode<K,V> hd = null, tl = null;
do {
TreeNode<K,V> p = replacementTreeNode(e, null);
if (tl == null)
hd = p;
else {
p.prev = tl;
tl.next = p;
}
tl = p;
} while ((e = e.next) != null);
if ((tab[index] = hd) != null)
hd.treeify(tab);
}
}
为什么选择树化的长度是 8,泊松分布
* 0: 0.60653066
* 1: 0.30326533
* 2: 0.07581633
* 3: 0.01263606
* 4: 0.00157952
* 5: 0.00015795
* 6: 0.00001316
* 7: 0.00000094
* 8: 0.00000006
* more: less than 1 in ten million
普通节点
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
Node(int hash, K key, V value, Node<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
}
树形节点
static final class TreeNode<K,V> extends LinkedHashMap.Entry<K,V> {
TreeNode<K,V> parent; // red-black tree links
TreeNode<K,V> left;
TreeNode<K,V> right;
TreeNode<K,V> prev; // needed to unlink next upon deletion
boolean red;
}
static class Entry<K,V> extends HashMap.Node<K,V> {
Entry<K,V> before, after;
Entry(int hash, K key, V value, Node<K,V> next) {
super(hash, key, value, next);
}
}
思考题:
1、hashmap 的 key 的 hash 怎么计算?
2、hashmap 的 hash 表什么情况下会扩容?
3、hashmap 中什么时候会树化?
4、为什么选择 0.75 为负载因子,8 为树化阈值?
4、hashset
只要理解了 hashmap,hashset 不攻自破。
(1)首先我们看到 hashset 内部维护了一个 hashmap,其实说明了 hashset 的实现是基于 hashmap 的。
private transient HashMap<E,Object> map;
(2)我们看到 hashset 的构造器其实只是 new 了一个 hashmap();
public HashSet() {
map = new HashMap<>();
}
(3)我们以添加为例
private static final Object PRESENT = new Object();
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}
四、集合的遍历
1、普通 for 循环
能够使用普通 for 循环的前提是必须可以通过下标获取数据,List 天然满足这个特性。
public class ListTest {
public static void main(String[] args) {
public List<String> names;
names = new ArrayList<>();
names.add("lucy");
names.add("tom");
names.add("jerry");
for (int i = 0; i < names.size(); i++) {
System.out.println(names.get(i));
}
}
}
同理:
我们将 names = new ArrayList<>();改为names = new LinkedList<>();也是可以的。
思考问题:
hashmap 和 hashset 怎么进行遍历?它们没有下标啊。
这里就必须使用迭代器了。
2、迭代器
(1)迭代器介绍
迭代器其实是一种思想。
先看一下迭代器这个接口:
public interface Iterator<E> {
// 是不是有下一个
boolean hasNext();
// 拿到下一个
E next();
// 你可以继承重写这个方法,否则将抛出异常
default void remove() {
throw new UnsupportedOperationException("remove");
}
}
例如:

小丽拿了一篮子苹果,你想把小丽的苹果分给大家吃。
- 我:小丽,篮子里还有吗?
- 小丽: 有呢。
hasNext() - 我:给我。
- 小丽:好呢。
next() - 小丽:哎,这个坏了,我扔了吧!
remove()
其实小丽就是我们所说的迭代器。
(2)迭代器的使用
还是上边的例子:
@Test
public void testIterator(){
Iterator<String> iterator = names.iterator();
// 每次都判断一下是不是有下一个,有的话,继续遍历
while (iterator.hasNext()){
// 获取下一个
String name = iterator.next();
System.out.println(name);
}
}
当然换成 LinkedList 也是可行的。
看看 hashSet,居然也行
/**
* @author itnanls
* @date 2021/7/16
**/
public class SetTest {
public Set<String> names;
@Before
public void add() {
names = new HashSet<>();
names.add("lucy");
names.add("tom");
names.add("jerry");
}
@Test
public void testIterator(){
Iterator<String> iterator = names.iterator();
// 每次都判断一下是不是有下一个,有的话,继续遍历
while (iterator.hasNext()){
// 获取下一个
String name = iterator.next();
System.out.println(name);
}
}
}
再看看 hashmap,也是可以的
public class MapTest {
public Map<String,String> user;
@Before
public void add() {
user = new HashMap<>();
user.put("username","ydlclass");
user.put("password","ydl666888");
}
@Test
public void testIterator(){
// 拿到一个存有所有entry的set集合。
// entry就是一个个的节点node
Set<Map.Entry<String, String>> entries = user.entrySet();
Iterator<Map.Entry<String, String>> iterator = entries.iterator();
while (iterator.hasNext()){
Map.Entry<String, String> next = iterator.next();
System.out.println(next.getKey());
System.out.println(next.getValue());
}
}
}
也可以先获取一个 key 的 set 即可,再用迭代器进行遍历。
这种方式相当于遍历了两次,效率低。
@Test
public void testIterator2(){
// 获取一个含有所有key的set集合,去迭代
Set<String> keys = user.keySet();
Iterator<String> iterator = keys.iterator();
while (iterator.hasNext()){
String key = iterator.next();
System.out.println(key);
System.out.println(user.get(key));
}
}
千万别以为迭代器牛逼的不行,其实迭代器只是个接口,每个对象都要有对应的实现。
简单的看一下 arraylist 的实现
private class Itr implements Iterator<E> {
// 只要有标没到最后一个就行
public boolean hasNext() {
return cursor != size();
}
public E next() {
checkForComodification();
try {
// 大概率就是使用游标控制下一个的位置
int i = cursor;
// 其实就是返回了下一个
E next = get(i);
lastRet = i;
cursor = i + 1;
return next;
} catch (IndexOutOfBoundsException e) {
checkForComodification();
throw new NoSuchElementException();
}
}
public void remove() {
if (lastRet < 0)
throw new IllegalStateException();
checkForComodification();
try {
// 直接把当前的删除就行了
AbstractList.this.remove(lastRet);
if (lastRet < cursor)
cursor--;
lastRet = -1;
expectedModCount = modCount;
} catch (IndexOutOfBoundsException e) {
throw new ConcurrentModificationException();
}
}
final void checkForComodification() {
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
}
}
3、增强 for 循环
Java 提供了一种语法糖(用起来甜甜的,很简单)去帮助我们遍历,叫增强 for 循环:
List、Set 都可以使用这种方式进行遍历:
@Test
public void testEnhancedFor(){
for (String name : names){
System.out.println(name);
}
}
Map 使用这样的写法:
@Test
public void testEnhancedFor(){
for (Map.Entry<String,String> entry : user.entrySet()){
System.out.println(entry.getKey());
System.out.println(entry.getValue());
}
}
增强 for 循环其实也是使用了迭代器。我们可以在 ArrayList 中的迭代器中打一个断点,debug 运行一下即可。
增强 for 循环只是一种语法糖,用起来甜甜的简单而已。

4、迭代中删除元素
有同一个题目:我想把下边的集合中的 lucy 全部删除?
public void add() {
List<String> names = new ArrayList<>();
names.add("tom");
names.add("lucy");
names.add("lucy");
names.add("lucy");
names.add("jerry");
}
(1)for 循环中删除
public void testDelByFor(){
for (int i = 0; i < names.size(); i++) {
if("lucy".equals(names.get(i))){
names.remove(i);
}
}
System.out.println(names);
}
结果:
[tom, lucy, jerry]
我们发现并没有删除干净,中间的 lucy 好像被遗忘了。

合适的解决方式有两种:
第一种:回调指针
for (int i = 0; i < names.size(); i++) {
if("lucy".equals(names.get(i))){
names.remove(i);
// 回调指针:
i--;
}
}
System.out.println(names);
结果:
[tom, jerry]
第二种:逆序遍历
for (int i = names.size()-1; i > 0; i--) {
if("lucy".equals(names.get(i))){
names.remove(i);
}
}
System.out.println(names);
结果:
[tom, jerry]
但是最好的删除方法是使用迭代器。
(2)使用迭代器删除元素
public static void main(String[] args){
Iterator<String> iterator = names.iterator();
while (iterator.hasNext()){
// 记住next(),只能调用一次,因为每次调用都会选择下一个
String name = iterator.next();
if("lucy".equals(name)){
iterator.remove();
}
}
System.out.println(names);
}
五、其他的集合类
1、Linkedhashmap
Linkedhashmap 在原来的基础上维护了一个双向链表,用来维护,插入的顺序。
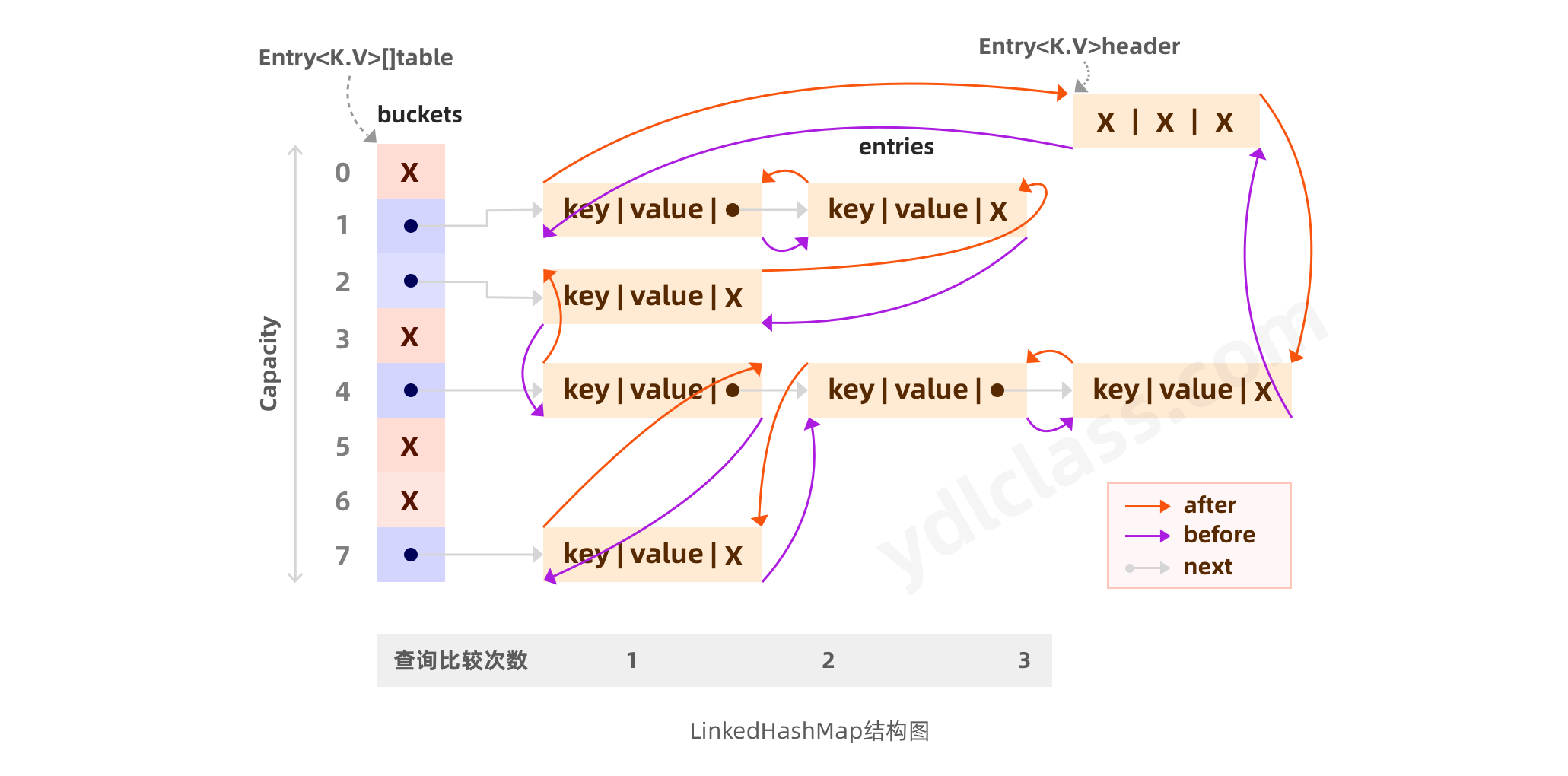
public class LinkedHashMapTest {
public static void main(String[] args){
Map<String,String> map = new LinkedHashMap<>(16);
map.put("m","abc");
map.put("a","abc");
map.put("g","bcd");
map.put("s","cde");
map.put("z","def");
Iterator<Map.Entry<String, String>> iterator = map.entrySet().iterator();
while (iterator.hasNext()){
Map.Entry<String, String> next = iterator.next();
System.out.print(next.getKey() + " ");
System.out.println(next.getValue());
}
}
}
结果:结果是有序的
m abc
a abc
g bcd
s cde
z def
Map<String,String> map = new HashMap<>();
如果换成hashmap的结果是:很明显无序
a abc
s cde
g bcd
z def
m abc
public LinkedHashMap() {
super();
accessOrder = false;
}
static class Entry<K,V> extends HashMap.Node<K,V> {
Entry<K,V> before, after;
Entry(int hash, K key, V value, Node<K,V> next) {
super(hash, key, value, next);
}
}
transient LinkedHashMap.Entry<K,V> head;
/**
* The tail (youngest) of the doubly linked list.
*/
transient LinkedHashMap.Entry<K,V> tail;
如果 accessOrder 为true的话,则会把访问过的元素放在链表后面,放置顺序是访问的顺序 如果 accessOrder 为flase的话,则按插入顺序来遍历
在 Linkedhashmap 中有几个顺序,一个是插入顺序,一个是访问顺序。
我们还可以使用 linkedhashmap 实现 LRU 算法的缓存,所谓LRU:Least Recently Used,最近最少使用,即当缓存了,会优先淘汰那些最近不常访问的数据.即冷数据优先淘汰.
public class LRU<K,V> extends LinkedHashMap<K,V> {
private int max_capacity;
public LRU(int initialCapacity,int max_capacity) {
super(initialCapacity, 0.75F, true);
this.max_capacity = max_capacity;
}
public LRU() {
super(16, 0.75F, true);
max_capacity = 8;
}
@Override
protected boolean removeEldestEntry(Map.Entry<K, V> eldest) {
return size() > max_capacity;
}
}
2、TreeMap
TreeMap 底层实现是红黑树,所以天然支持排序。
public TreeMap() {
comparator = null;
}
public TreeMap(Comparator<? super K> comparator) {
this.comparator = comparator;
}
final int compare(Object k1, Object k2) {
return comparator==null ? ((Comparable<? super K>)k1).compareTo((K)k2)
: comparator.compare((K)k1, (K)k2);
}
会吧key1强转为Comparable
我们尝试把一个没有实现 Comparable 的类传入 TreeMap 中,发现会抛出异常。
Map<Dog,String> map = new TreeMap<>();
for (int i = 0; i < 100; i++) {
map.put(new Dog(),"a");
}
Exception in thread "main" java.lang.ClassCastException: bb.Dog cannot be cast to java.lang.Comparable
at java.util.TreeMap.compare(TreeMap.java:1294)
at java.util.TreeMap.put(TreeMap.java:538)
at bb.Animal.main(Animal.java:14)
已经很明显了,这就是我们之前学习的策略设计模式啊,我们可以自定义比较器,实现 key 的有序性。
public static void main(String[] args) {
Map<Integer,String> map = new TreeMap<>(new Comparator<Integer>() {
@Override
public int compare(Integer o1, Integer o2) {
return o1 - o2;
}
});
for (int i = 0; i < 100; i++) {
map.put(i,"a");
}
System.out.println(map);
}
{0=a, 1=a, 2=a, 3=a, 4=a, 5=a, 6=a, 7=a, 8=a, 9=a, 10=a, 11=a, 12=a, 13=a, 14=a, 15=a,
我们修改一个比较器,立马就发生了变化。
return o2 - o1;
{99=a, 98=a, 97=a, 96=a, 95=a, 94=a, 93=a, 92=a, 91=a, 90=a, 89=a
我们当然可以让 Dog 类实现 Comparable 接口来使 Dog 作为 key 传入 Map 中。
3、Collections
Collections 是一个工具类,它给我们提供了一些常用的好用的操作集合的方法。
ArrayList<Integer> list = new ArrayList<>();
list.add(12);
list.add(4);
list.add(3);
list.add(5);
//将集合按照默认的规则排序,按照数字从小到大的顺序排序
Collections.sort(list);
System.out.println("list = " + list);
System.out.println("===================");
//将集合中的元素反转
Collections.reverse(list);
System.out.println("list = " + list);
//addAll方法可以往集合中添加元素,也可往集合中添加一个集合
Collections.addAll(list,9,20,56);
//打乱集合中的元素
Collections.shuffle(list);
System.out.println("list = " + list);
//Arrays.asList方法可以返回一个长度内容固定的List集合
List<String> list2 = Arrays.asList("tom", "kobe", "jordan", "tracy","westbook","yaoming","ace","stephen");
//按照字符串首字符的升序排列
Collections.sort(list2);
小问题:
Arrays.asList(...)返回的是 ArrayList 吗?
六、线程安全问题
1、并发修改异常
使用增强 for 循环中删除元素会抛异常
public void testDelByEnhancedFor(){
for (String name : names){
if("lucy".equals(name)){
names.remove(name);
}
}
}
// 并发修改异常
java.util.ConcurrentModificationException
at java.util.ArrayList$Itr.checkForComodification(ArrayList.java:909)
at java.util.ArrayList$Itr.next(ArrayList.java:859)
at com.ydlclass.ListTest.testDelByEnhancedFor(ListTest.java:51)
......
其实不仅仅是上边的情况,下边的情况也会出现:
public void addDelByEnhancedFor(){
for (String name : names){
if("lucy".equals(name)){
names.add(name);
}
}
}
public void testDelByIterator(){
Iterator<String> iterator = names.iterator();
while (iterator.hasNext()){
// 记住next(),只能调用一次,因为每次调用都会选择下一个
String name = iterator.next();
if("lucy".equals(name)){
names.add("hello");
}
}
System.out.println(names);
}
产生的原因:
我们可以把普通的方法和迭代器的方法看成两个人,一个小丽,一个小红。
你用小丽迭代的时候,用小红的方法删除,或者用小红的方法迭代,用小丽的方法删除就会出错。
迭代器是依赖于集合而存在的,在判断成功后,集合的中新添加了元素,而迭代器却不知道,所以就报错了,这个错叫并发修改异常。
如何解决呢?
- 迭代器迭代元素,迭代器修改元素。
- 集合遍历元素,集合修改元素(普通 for)。
2、数据错误的问题
我们学了并发编程,知道当多个线程同时操作共享资源时会有线程安全问题。
public static void main(String[] args) throws InterruptedException {
final ArrayList<Integer> list = new ArrayList<>();
CountDownLatch countDownLatch = new CountDownLatch(200);
for (int i = 0; i < 200; i++) {
new Thread(()->{
try {
Thread.sleep(10);
} catch (InterruptedException e) {
e.printStackTrace();
}
list.add(1);
countDownLatch.countDown();
}).start();
}
countDownLatch.await();
System.out.println(list.size());
}
第一次,我们居然发现 arraylist 也会有空指针,盲猜大概是,获取大小的时候没问题,插入的时候有人捷足先登,你就插不进去了。
Exception in thread "Thread-193" java.lang.ArrayIndexOutOfBoundsException: 163
at java.util.ArrayList.add(ArrayList.java:463)
at aaa.Test.lambda$main$0(Test.java:21)
at java.lang.Thread.run(Thread.java:748)
第二次
195
那怎么解决线程安全的问题啊。
加锁,其实 JDK 开始也是这样想的,于是有这两个类。
3、加锁解决
HashTable 和 Vector,这是两个很古老的类
HashTable
public class Hashtable<K,V>
extends Dictionary<K,V>
implements Map<K,V>, Cloneable, java.io.Serializable {
public synchronized V get(Object key) {
Entry<?,?> tab[] = table;
int hash = key.hashCode();
int index = (hash & 0x7FFFFFFF) % tab.length;
for (Entry<?,?> e = tab[index] ; e != null ; e = e.next) {
if ((e.hash == hash) && e.key.equals(key)) {
return (V)e.value;
}
}
return null;
}
}
Vector
public class Vector<E>
extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable
public synchronized int size() {
return elementCount;
}
public synchronized boolean add(E e) {
modCount++;
ensureCapacityHelper(elementCount + 1);
elementData[elementCount++] = e;
return true;
}
public synchronized boolean removeElement(Object obj) {
modCount++;
int i = indexOf(obj);
if (i >= 0) {
removeElementAt(i);
return true;
}
return false;
}
这两个类,其实很久没更新了,但是还是有面试会问,其实这两个类都有历史渊源,最开始就是在 ArrayList 和 HashMap 的基础上增加了 Syncronized,但是后来 ArrayList 和 hashMap 一直在改进,这两个就成了历史了,反而现在问它们的区别其实意义不大了。
HashMap 和 HashTable 区别
- HashMap 允许将 null 作为一个 entry 的 key 或者 value,而 Hashtable 不允许。
- HashMap 把 Hashtable 的 contains 方法去掉了,改成 containsValue 和 containsKey。因为 contains 方法容易让人引起误解。
- HashTable 继承自 Dictionary 类,而 HashMap 是 Java1.2 引进的 Map interface 的一个实现。
- HashTable 的方法是 Synchronized 修饰 的,而 HashMap 不是,这也是是否能保证线程安全的重要保障。
- Hashtable 和 HashMap 采用的 hash/rehash 算法都不一样。
- 获取数组下标的算法不同,
ArrayList 和 Vector 的区别
- Vector 是多线程安全的,线程安全就是说多线程访问同一代码,不会产生不确定的结果。而 ArrayList 不是,这个可以从源码中看出,Vector 类中的方法很多,有 synchronized 进行修饰,这样就导致了 Vector 在效率上无法与 ArrayList 相比;
- 两个都是采用线性连续空间存储元素,但是当空间不足的时候,两个类的扩容方式是不同的。
- Vector 是一种老的动态数组,是线程同步的,效率很低,一般不赞成使用。
4、目前常用的线程安全集合
(1)CopyOnWriteList
目前我们有更好的解决方案:
CopyOnWriteList 的核心就是写入的时候加锁,保证线程安全,读取的时候不加锁。不是一股脑,给所有的方法加锁。
public boolean add(E e) {
final ReentrantLock lock = this.lock;
lock.lock();
try {
// 复制一个新的数组,在新的独立空间进行添加操作
Object[] elements = getArray();
int len = elements.length;
Object[] newElements = Arrays.copyOf(elements, len + 1);
newElements[len] = e;
// 修改引用
setArray(newElements);
return true;
} finally {
lock.unlock();
}
}
final void setArray(Object[] a) {
array = a;
}
(2)ConcurrentHashMap
1.8 中的 ConcurrentHashMap 和 HashMap 的代码基本一样,只不过在有些操作上使用了 cas,有些地方加了锁。
public class ConcurrentHashMap<K,V> extends AbstractMap<K,V>
implements ConcurrentMap<K,V>, Serializable {
构造器:
public ConcurrentHashMap(int initialCapacity) {
if (initialCapacity < 0)
throw new IllegalArgumentException();
int cap = ((initialCapacity >= (MAXIMUM_CAPACITY >>> 1)) ?
MAXIMUM_CAPACITY :
tableSizeFor(initialCapacity + (initialCapacity >>> 1) + 1));
this.sizeCtl = cap;
}
我们简单看看 putVal 算法
final V putVal(K key, V value, boolean onlyIfAbsent) {
if (key == null || value == null) throw new NullPointerException();
// 计算hash
int hash = spread(key.hashCode());
int binCount = 0;
for (Node<K,V>[] tab = table;;) {
Node<K,V> f; int n, i, fh;
// 如果没有hash表,就创建一个
if (tab == null || (n = tab.length) == 0)
tab = initTable();
// 给f赋值就是hash表中的元素
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
// 这里也是线程安全的
// 如果没有就使用cas的方式添加
if (casTabAt(tab, i, null,
new Node<K,V>(hash, key, value, null)))
break; // no lock when adding to empty bin
}
else if ((fh = f.hash) == MOVED)
tab = helpTransfer(tab, f);
else {
V oldVal = null;
// 看这是关键,这加了锁,f是什么啊?
// f是头节点
synchronized (f) {
if (tabAt(tab, i) == f) {
if (fh >= 0) {
binCount = 1;
for (Node<K,V> e = f;; ++binCount) {
K ek;
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break;
}
Node<K,V> pred = e;
if ((e = e.next) == null) {
pred.next = new Node<K,V>(hash, key,
value, null);
break;
}
}
}
else if (f instanceof TreeBin) {
Node<K,V> p;
binCount = 2;
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,
value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
}
}
if (binCount != 0) {
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;
}
}
}
addCount(1L, binCount);
return null;
}
其实,面试很喜欢问 1.7 和 1.8 的区别
主要是 1.7 的分段锁是一个很经典的案例,造成这个的原因还有一个更重要的就是 JDK1.7 使用的是头插,而 1.8 改成尾插
我们简单的看一下 1.7 的 put 方法实现:
public V put(K key, V value) {
if (key == null)
return putForNullKey(value);
int hash = hash(key);
int i = indexFor(hash, table.length);
// 找到相同的key,覆盖
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
// 否则就是新增
addEntry(hash, key, value, i);
return null;
}
void addEntry(int hash, K key, V value, int bucketIndex) {
// 判断是否需要扩容
if ((size >= threshold) && (null != table[bucketIndex])) {
resize(2 * table.length);
hash = (null != key) ? hash(key) : 0;
bucketIndex = indexFor(hash, table.length);
}
// 创建
createEntry(hash, key, value, bucketIndex);
}
void createEntry(int hash, K key, V value, int bucketIndex) {
Entry<K,V> e = table[bucketIndex];
// 头插啊
table[bucketIndex] = new Entry<>(hash, key, value, e);
size++;
}
// 1.7中居然直接就是Entry不是node
Entry(int h, K k, V v, Entry<K,V> n) {
value = v;
next = n;
key = k;
hash = h;
}
JDK8 以前是头插法,JDK8 后是尾插法,那为什么要从头插法改成尾插法?
- 因为头插法会造成循环链表
- JDK7 用头插是考虑到了一个所谓的热点数据的点(新插入的数据可能会更早用到),但这其实是个伪命题,因为 JDK7 中 rehash 的时候,旧链表迁移新链表的时候,如果在新表的数组索引位置相同,则链表元素会倒置(就是因为头插), 所以最后的结果 还是打乱了插入的顺序 ,所以总的来看支撑 JDK7 使用头插的这点原因也不足以支撑下去了 ,所以就干脆换成尾插 一举多得。
1.7 的加锁实现
/**
* Mask value for indexing into segments. The upper bits of a
* key's hash code are used to choose the segment.
*/
final int segmentMask;
/**
* Shift value for indexing within segments.
*/
final int segmentShift;
/**
* The segments, each of which is a specialized hash table.
*/
final Segment<K,V>[] segments;
transient Set<K> keySet;
transient Set<Map.Entry<K,V>> entrySet;
transient Collection<V> values;
static final class Segment<K,V> extends ReentrantLock implements Serializable {
private static final long serialVersionUID = 2249069246763182397L;
static final int MAX_SCAN_RETRIES =
Runtime.getRuntime().availableProcessors() > 1 ? 64 : 1;
// 我们陡然发现每一个分段里边保存了一个数组,这不就是数组套数组吗?
transient volatile HashEntry<K,V>[] table;
transient int count;
final float loadFactor;
@SuppressWarnings("unchecked")
public ConcurrentHashMap(int initialCapacity,
float loadFactor, int concurrencyLevel) {
if (!(loadFactor > 0) || initialCapacity < 0 || concurrencyLevel <= 0)
throw new IllegalArgumentException();
if (concurrencyLevel > MAX_SEGMENTS)
concurrencyLevel = MAX_SEGMENTS;
// Find power-of-two sizes best matching arguments
int sshift = 0;
int ssize = 1;
while (ssize < concurrencyLevel) {
++sshift;
ssize <<= 1;
}
this.segmentShift = 32 - sshift;
this.segmentMask = ssize - 1;
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
int c = initialCapacity / ssize;
if (c * ssize < initialCapacity)
++c;
int cap = MIN_SEGMENT_TABLE_CAPACITY;
while (cap < c)
cap <<= 1;
// create segments and segments[0]
Segment<K,V> s0 =
new Segment<K,V>(loadFactor, (int)(cap * loadFactor),
(HashEntry<K,V>[])new HashEntry[cap]);
Segment<K,V>[] ss = (Segment<K,V>[])new Segment[ssize];
UNSAFE.putOrderedObject(ss, SBASE, s0); // ordered write of segments[0]
this.segments = ss;
}
public V put(K key, V value) {
Segment<K,V> s;
if (value == null)
throw new NullPointerException();
int hash = hash(key);
int j = (hash >>> segmentShift) & segmentMask;
if ((s = (Segment<K,V>)UNSAFE.getObject // nonvolatile; recheck
(segments, (j << SSHIFT) + SBASE)) == null) // in ensureSegment
s = ensureSegment(j);
return s.put(key, hash, value, false);
}
final V put(K key, int hash, V value, boolean onlyIfAbsent) {
// 先尝试加锁,加不上再疯狂加锁,反正能加上锁,他继承了ReentrantLock
HashEntry<K,V> node = tryLock() ? null :
scanAndLockForPut(key, hash, value);
V oldValue;
try {
HashEntry<K,V>[] tab = table;
int index = (tab.length - 1) & hash;
HashEntry<K,V> first = entryAt(tab, index);
for (HashEntry<K,V> e = first;;) {
if (e != null) {
K k;
if ((k = e.key) == key ||
(e.hash == hash && key.equals(k))) {
oldValue = e.value;
if (!onlyIfAbsent) {
e.value = value;
++modCount;
}
break;
}
e = e.next;
}
else {
if (node != null)
node.setNext(first);
else
node = new HashEntry<K,V>(hash, key, value, first);
int c = count + 1;
if (c > threshold && tab.length < MAXIMUM_CAPACITY)
rehash(node);
else
setEntryAt(tab, index, node);
++modCount;
count = c;
oldValue = null;
break;
}
}
} finally {
unlock();
}
return oldValue;
}
private HashEntry<K,V> scanAndLockForPut(K key, int hash, V value) {
HashEntry<K,V> first = entryForHash(this, hash);
HashEntry<K,V> e = first;
HashEntry<K,V> node = null;
int retries = -1; // negative while locating node
// 不定的重新抢锁,抢锁的过程当中完成很多初始化的工作
while (!tryLock()) {
HashEntry<K,V> f; // to recheck first below
// 第一次再次抢锁时顺便初始化了entry
if (retries < 0) {
if (e == null) {
if (node == null) // speculatively create node
node = new HashEntry<K,V>(hash, key, value, null);
retries = 0;
}
// 发现重复的key就不用初识化entry了
else if (key.equals(e.key))
retries = 0;
else
e = e.next;
}
// 如果超过最大的抢锁的次数直接调用lock
else if (++retries > MAX_SCAN_RETRIES) {
lock();
break;
}
else if ((retries & 1) == 0 &&
(f = entryForHash(this, hash)) != first) {
e = first = f; // re-traverse if entry changed
retries = -1;
}
}
return node;
}
5、guava 提供的不可变集合
Immutable..等类,天然支持线程安全
ImmutableList
public class GuavaTest {
public static void main(String[] args) {
String[] strings = {"a","b","c"};
ImmutableList<String> list = ImmutableList.copyOf(strings);
for (String s : list) {
System.out.println(s);
}
}
}
ImmutableMultimap
public class GuavaTest {
public static void main(String[] args) {
ImmutableMultimap<String, Integer> list = ImmutableMultimap.of("a",1,"b",2);
for (String s : list.keySet()) {
System.out.println("s = " + s);;
}
}
}
七、JUnit 单元测试
1、JUnit 入门
JUnit 是一个 Java 编程语言的单元测试框架。JUnit 在测试驱动的开发方面有很重要的发展,是起源于 JUnit 的一个统称为 xUnit 的单元测试框架之一。 JUnit 的好处:
- 可以书写一系列的测试方法,对项目所有的接口或者方法进行单元测试。
- 启动后,自动化测试,并判断执行结果, 不需要人为的干预。
- 只需要查看最后结果,就知道整个项目的方法接口是否通畅。
- 每个单元测试用例相对独立,由 Junit 启动,自动调用。不需要添加额外的调用语句。
- 添加,删除,屏蔽测试方法,不影响其他的测试方法。 开源框架都对 JUnit 有相应的支持。
JUnit 其实就是一个 jar 包,idea 中可以通过自动修复功能直接添加。但是为了演示清楚,我们还是安装规矩引入 jar 包完成。
使用 JUnit 我们需要引入下边两个 jar 包即可:
- hamcrest-core-1.1.jar
- junit-4.12.jar
网站有提供。
加入 JUnit 后,我们可以创建测试类,测试方法,每一个测试方法都可以独立运行:
2、JUnit 断言
Junit 所有的断言都包含在 Assert 类中。
这个类提供了很多有用的断言方法来编写测试用例。只有失败的断言才会被记录。Assert 类中的一些有用的方法列式如下:
void assertEquals(boolean expected, boolean actual):检查两个变量或者等式是否平衡void assertTrue(boolean expected, boolean actual):检查条件为真void assertFalse(boolean condition):检查条件为假void assertNotNull(Object object):检查对象不为空void assertNull(Object object):检查对象为空void assertSame(boolean condition):assertSame() 方法检查两个相关对象是否指向同一个对象void assertNotSame(boolean condition):assertNotSame() 方法检查两个相关对象是否不指向同一个对象void assertArrayEquals(expectedArray, resultArray):assertArrayEquals() 方法检查两个数组是否相等
断言不成功会抛出异常,会有红色的进度条,断言能够帮助我们很好的预判结果,即使程序正常运行但是结果不正确,也会以失败结束。
3、JUnit 注解
@Test:这个注释说明依附在 JUnit 的 public void 方法可以作为一个测试案例。@Before:有些测试在运行前需要创造几个相似的对象。在 public void 方法加该注释是因为该方法需要在 test 方法前运行。@After:如果你将外部资源在 Before 方法中分配,那么你需要在测试运行后释放他们。在 public void 方法加该注释是因为该方法需要在 test 方法后运行。
public class JunitTest {
@Before
public void before(){
System.out.println("before junit!");
}
@Test
public void print(){
System.out.println("hello junit!");
}
@After
public void after(){
System.out.println("after junit!");
}
}

4、命名规范
单元测试类的命名规范为:被测试类的类名+Test。.
单元测试类中测试方法的命名规范为:test+被测试方法的方法名+AAA,其中 AAA 为对同一个方法的不同的单元测试用例的自定义名称。.
六、性能对比
1、Hashtable 和 ConcurrentHashMap
我们尝试开辟 50 个线程,每个线程向集合中 put100000 个元素,测试两个类所需要的时间。
@Test
public void hashtableTest() throws InterruptedException {
final Map<Integer,Integer> map = new Hashtable<>(500000);
final CountDownLatch countDownLatch = new CountDownLatch(50);
System.out.println("----------------开始测试Hashtable------------------");
long start = System.currentTimeMillis();
for (int i = 0; i < 50; i++) {
final int j = i;
new Thread(()->{
for (int k = 0; k < 100000; k++) {
map.put(j*k,1);
}
countDownLatch.countDown();
}).start();
}
countDownLatch.await();
long end = System.currentTimeMillis();
System.out.println("hashtable:(end-start) = " + (end - start));
// ----------------开始测试ConcurrentHashMap------------------
System.out.println("----------------开始测试ConcurrentHashMap------------------");
final Map map2 = new ConcurrentHashMap<>(500000);
final CountDownLatch countDownLatch2 = new CountDownLatch(50);
start = System.currentTimeMillis();
for (int i = 0; i < 50; i++) {
final int j = i;
new Thread(()->{
for (int k = 0; k < 100000; k++) {
map2.put(j*k,1);
}
countDownLatch2.countDown();
}).start();
}
countDownLatch.await();
end = System.currentTimeMillis();
System.out.println("ConcurrentHashMap:(end-start) = " + (end - start));
}
得到的结果:性能真的差距很大
----------------开始测试Hashtable------------------
hashtable:(end-start) = 777
----------------开始测试ConcurrentHashMap------------------
ConcurrentHashMap:(end-start) = 2
2、arraylist 和 linkedlist
(1)顺序添加,尾插
@Test
public void testArrayListAdd(){
List<Integer> list = new ArrayList<>();
Long start = System.currentTimeMillis();
for (int i = 0; i < 10000000; i++) {
list.add((int)(Math.random()*100));
}
Long end = System.currentTimeMillis();
System.out.printf("用时%d毫秒。",end-start);
}
结果:
用时243毫秒。
@Test
public void testLinkedListAdd(){
List<Integer> list = new LinkedList<>();
Long start = System.currentTimeMillis();
for (int i = 0; i < 10000000; i++) {
list.add((int)(Math.random()*100));
}
Long end = System.currentTimeMillis();
System.out.printf("用时%d毫秒。",end-start);
}
结果:
用时2524毫秒。
(2)使用 for 循环迭代获取
@Test
public void testArrayListFor(){
List<Integer> list = new ArrayList<>();
for (int i = 0; i < 10000000; i++) {
list.add((int)(Math.random()*100));
}
System.out.println("开始------");
Long start = System.currentTimeMillis();
for (int i = 0; i < list.size(); i++) {
list.get(i);
}
Long end = System.currentTimeMillis();
System.out.printf("用时%d毫秒。",end-start);
}
结果:
用时2毫秒。
@Test
public void testLinkedListFor(){
List<Integer> list = new LinkedList<>();
for (int i = 0; i < 10000000; i++) {
list.add((int)(Math.random()*100));
}
System.out.println("开始------");
Long start = System.currentTimeMillis();
for (int i = 0; i < list.size(); i++) {
list.get(i);
}
Long end = System.currentTimeMillis();
System.out.printf("用时%d毫秒。",end-start);
}
结果:
无法计算时间。
(3)使用迭代器迭代获取
@Test
public void testArrayListIterator(){
List<Integer> list = new ArrayList<>();
for (int i = 0; i < 10000000; i++) {
list.add((int)(Math.random()*100));
}
System.out.println("开始------");
Long start = System.currentTimeMillis();
Iterator<Integer> iterator = list.iterator();
while (iterator.hasNext()){
iterator.next();
}
Long end = System.currentTimeMillis();
System.out.printf("用时%d毫秒。",end-start);
}
结果:
开始------
用时4毫秒。
@Test
public void testLinkedListIterator(){
List<Integer> list = new LinkedList<>();
for (int i = 0; i < 10000000; i++) {
list.add((int)(Math.random()*100));
}
System.out.println("开始------");
Long start = System.currentTimeMillis();
Iterator<Integer> iterator = list.iterator();
while (iterator.hasNext()){
iterator.next();
}
Long end = System.currentTimeMillis();
System.out.printf("用时%d毫秒。",end-start);
}
结果:
开始------
用时42毫秒。
(4)头插
@Test
public void testArrayListAddHeader(){
List<Integer> list = new ArrayList<>();
Long start = System.currentTimeMillis();
for (int i = 0; i < 10000000; i++) {
list.add(0,(int)(Math.random()*100));
}
Long end = System.currentTimeMillis();
System.out.printf("用时%d毫秒。",end-start);
}
结果:
无法算出,太慢
@Test
public void testLinkedListAddHeader(){
List<Integer> list = new LinkedList<>();
Long start = System.currentTimeMillis();
for (int i = 0; i < 10000000; i++) {
list.add(0,(int)(Math.random()*100));
}
Long end = System.currentTimeMillis();
System.out.printf("用时%d毫秒。",end-start);
}
结果:
用时2487毫秒。
(5)随机删除
@Test
public void testLinkedListDel(){
List<Integer> list = new LinkedList<>();
for (int i = 0; i < 10000000; i++) {
list.add(0,(int)(Math.random()*100));
}
Long start = System.currentTimeMillis();
Iterator<Integer> iterator = list.iterator();
while (iterator.hasNext()){
if(iterator.next()>5000000){
iterator.remove();
}
}
Long end = System.currentTimeMillis();
System.out.printf("用时%d毫秒。",end-start);
}
结果:
用时45毫秒。
@Test
public void testArrayListDel(){
List<Integer> list = new ArrayList<>();
for (int i = 0; i < 10000000; i++) {
list.add(0,(int)(Math.random()*100));
}
Long start = System.currentTimeMillis();
Iterator<Integer> iterator = list.iterator();
while (iterator.hasNext()){
if(iterator.next()>5000000){
iterator.remove();
}
}
Long end = System.currentTimeMillis();
System.out.printf("用时%d毫秒。",end-start);
}
结果:
太慢,时间没出来
(6)自带的排序方法
排序比较耗费资源,所以我们把量级调整到了十万。
@Test
public void testArrayListSort(){
List<Integer> list = new ArrayList<>();
for (int i = 0; i < 100000; i++) {
list.add(0,(int)(Math.random()*100));
}
Long start = System.currentTimeMillis();
// 不用管为啥,这就是排序,复制过来用就行,写个冒泡也行
list.sort(Comparator.comparingInt(num -> num));
Long end = System.currentTimeMillis();
System.out.printf("用时%d毫秒。",end-start);
}
结果:
用时49毫秒。
@Test
public void testLinkedListSort(){
List<Integer> list = new LinkedList<>();
for (int i = 0; i < 100000; i++) {
list.add(0,(int)(Math.random()*100));
}
Long start = System.currentTimeMillis();
// 不用管为啥,这就是排序,复制过来用就行,写个冒泡也行
list.sort(Comparator.comparingInt(num -> num));
Long end = System.currentTimeMillis();
System.out.printf("用时%d毫秒。",end-start);
}
结果:
用时53毫秒。
(7)思考
其实我们学习时,总是去背诵概念:
数组查询快,插入慢。链表插入慢,查询快。
- 但是经过测试,尾插反而是数组快,而尾插的使用场景极多。
- 测试了各种迭代,遍历方法,ArrayList 基本都是比 LinkedList 要快。
- 随机插入,链表会快很多,确实有一些特殊的场景 LinkedList 更合适,比如以后我们学的过滤器链。
- 随机删除,链表的效率也是无比优于数组,如果我们存在需要过滤删除大量随机元素的场景也能使用 linkedlist。
- 我们工作中的使用还是以 ArrayList 为主,因为它的使用场景最多。
七、Java8 特性
1、接口默认方法
在 JDK8 之前,接口不能定义任何实现,这意味着之前所有的 JAVA 版本中,接口制定的方法是抽象的,不包含方法体。从 JKD8 开始,添加了一种新功能-默认方法。默认方法允许接口方法定义默认实现,而所有子类都将拥有该方法及实现。
默认方法的主要优势是提供一种拓展接口的方法,而不破坏现有代码。假如我们有一个已经投入使用接口,需要拓展一个新的方法,在 JDK8 以前,如果为一个使用的接口增加一个新方法,则我们必须在所有实现类中添加该方法的实现,否则编译会出现异常。如果实现类数量少并且我们有权限修改,可能会工作量相对较少。如果实现类比较多或者我们没有权限修改实现类源代码,这样可能就比较麻烦。而默认方法则解决了这个问题,它提供了一个实现,当没有显示提供其他实现时就采用这个实现。这样新添加的方法将不会破坏现有代码。
2、函数式接口
函数式接口在 Java 中是指:有且仅有一个抽象方法的接口
函数式接口,即适用于函数式编程场景的接口。而 Java 中的函数式编程体现就是 Lambda,所以函数式接口就是可以适用于 Lambda 使用的接口。只有确保接口中有且仅有一个抽象方法,Java 中的 Lambda 才能顺利地进行推导。
接下来给大家介绍几个常用的函数式接口,在我们接下来要学习的 Lamdba 表达式中大量使用。
消费者,消费数据
@FunctionalInterface
public interface Consumer<T> {
void accept(T t);
}
供应商,给我们产生数据
@FunctionalInterface
public interface Supplier<T> {
T get();
}
断言,判断传入的 t 是不是满足条件
@FunctionalInterface
public interface Predicate<T> {
boolean test(T t);
}
函数,就是将一个数据转化成另一个数据
@FunctionalInterface
public interface Function<T, R> {
R apply(T t);
}
我们在思考上边的代码的时候,不要胡思乱想,它们就是一组接口,和我们的普通接口一样,每个接口代表一种能力,需要子类去实现,因为它们是函数式接口,所以匿名内部类都可以写成箭头函数的形式。
3、Optional
(1)简介
Optional 类是 Java8 为了解决 null 值判断问题,借鉴 google guava 类库的 Optional 类而引入的一个同名 Optional 类,使用 Optional 类可以避免显式的 null 值判断(null 的防御性检查),避免 null 导致的NPE(NullPointerException)。
(2)Optional 对象的创建
Optional 类提供了三个静态方法empty()、of(T value)、ofNullable(T value)来创建 Optinal 对象,示例如下:
// 1、创建一个包装对象值为空的Optional对象
Optional<String> optStr = Optional.empty();
// 2、创建包装对象值非空的Optional对象
Optional<String> optStr1 = Optional.of("optional");
// 3、创建包装对象值允许为空的Optional对象
Optional<String> optStr2 = Optional.ofNullable(null);
(3)Optional 类典型接口的使用
下面以一些典型场景为例,列出 Optional API 常用接口的用法,并附上相应代码。
get()方法
简单看下get()方法的源码:
public T get() {
if (value == null) {
throw new NoSuchElementException("No value present");
}
return value;
}
可以看到,get()方法主要用于返回包装对象的实际值,但是如果包装对象值为 null,会抛出NoSuchElementException异常。
isPresent()方法
isPresent()方法的源码:
public boolean isPresent() {
return value != null;
}
可以看到,isPresent()方法用于判断包装对象的值是否非空。下面我们来看一段糟糕的代码:
public static String getGender(Student student){
Optional<Student> stuOpt = Optional.ofNullable(student);
if(stuOpt.isPresent())
{
return stuOpt.get().getGender();
}
return "Unkown";
}
这段代码实现的是第一章(简介)中的逻辑,但是这种用法不但没有减少 null 的防御性检查,而且增加了 Optional 包装的过程,违背了 Optional 设计的初衷,因此开发中要避免这种糟糕的使用
ifPresent()方法
ifPresent()方法的源码:
public void ifPresent(Consumer<? super T> consumer) {
if (value != null)
consumer.accept(value);
}
ifPresent()方法接受一个 Consumer 对象(消费函数),如果包装对象的值非空,运行 Consumer 对象的accept()方法。示例如下:
public static void printName(Student student){
Optional.ofNullable(student).ifPresent(u -> System.out.println("The student name is : " + u.getName()));
}
上述示例用于打印学生姓名,由于ifPresent()方法内部做了 null 值检查,调用前无需担心 NPE 问题。
orElse()方法
orElse()方法的源码:
public T orElse(T other) {
return value != null ? value : other;
}
orElse()方法功能比较简单,即如果包装对象值非空,返回包装对象值,否则返回入参 other 的值(默认值)。
public static String getGender(Student student){
return Optional.ofNullable(student).map(u -> u.getGender()).orElse("Unkown");
}
orElseGet()方法
orElseGet()方法的源码:
public T orElseGet(Supplier<? extends T> other) {
return value != null ? value : other.get();
}
orElseGet()方法与 orElse()方法类似,区别在于 orElseGet()方法的入参为一个 Supplier 对象,用 Supplier 对象的 get()方法的返回值作为默认值。如:
public static String getGender(Student student)
{
return Optional.ofNullable(student).map(u -> u.getGender()).orElseGet(() -> "Unkown");
}
orElseThrow()方法
orElseThrow()方法的源码:
public <X extends Throwable> T orElseThrow(Supplier<? extends X> exceptionSupplier) throws X {
if (value != null) {
return value;
} else {
throw exceptionSupplier.get();
}
}
orElseThrow()方法其实与orElseGet()方法非常相似了,入参都是 Supplier 对象,只不过orElseThrow()的 Supplier 对象必须返回一个 Throwable 异常,并在orElseThrow()中将异常抛出:
public static String getGender1(Student student){
return Optional.ofNullable(student).map(u -> u.getGender()).orElseThrow(() -> new RuntimeException("Unkown"));
}
orElseThrow()方法适用于包装对象值为空时需要抛出特定异常的场景。
八、Stream 编程
Java8 中的 Stream 是对容器对象功能的增强,它专注于对容器对象进行各种非常便利、高效的 聚合操作(aggregate operation),或者大批量数据操作 (bulk data operation)。Stream API 借助于同样新出现的 Lambda 表达式,极大的提高编程效率和程序可读性。同时,它提供串行和并行两种模式进行汇聚操作,并发模式能够充分利用多核处理器的优势。通常,编写并行代码很难而且容易出错, 但使用 Stream API 无需编写一行多线程的代码,就可以很方便地写出高性能的并发程序。
我觉得我们可以将流看做流水线,这个流水线是处理数据的流水线,一个产品经过流水线会有一道道的工序就如同对数据的中间操作,比如过滤我不需要的,给数据排序能,最后的终止操作就是产品从流水线下来,我们就可以统一打包放入仓库了。
当我们使用一个流的时候,通常包括三个基本步骤:获取一个数据源(source)→ 数据转换 → 执行操作获取想要的结果。每次转换原有 Stream 对象不改变,返回一个新的 Stream 对象(可以有多次转换),这就允许对其操作可以像链条一样排列,变成一个管道,如下图所示:
Stream 有几个特性:
- Stream 不存储数据,而是按照特定的规则对数据进行计算,一般会输出结果。
- Stream 不会改变数据源,通常情况下会产生一个新的集合或一个值。
- Stream 具有延迟执行特性,只有调用终端操作时,中间操作才会执行。
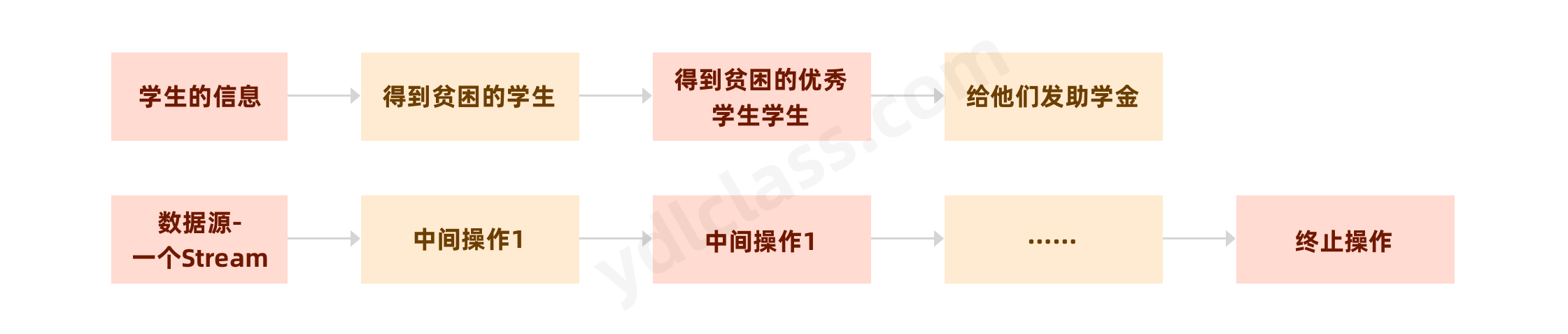
1、Stream 流的创建
(1)Stream 可以通过集合数组创建。
1、通过 java.util.Collection.stream() 方法用集合创建流,我们发现
default Stream<E> stream() {
return StreamSupport.stream(spliterator(), false);
}
List<String> list = Arrays.asList("a", "b", "c");
// 创建一个顺序流
Stream<String> stream = list.stream();
// 创建一个并行流
Stream<String> parallelStream = list.parallelStream();
(2)使用 java.util.Arrays.stream(T[] array)方法用数组创建流
int[] array={1,3,5,6,8};
IntStream stream = Arrays.stream(array);
(3)使用 Stream 的静态方法:of()、iterate()、generate()
Stream<Integer> stream = Stream.of(1, 2, 3, 4, 5, 6);
Stream<Integer> stream2 = Stream.iterate(0, (x) -> x + 3).limit(4);
stream2.forEach(System.out::println);
Stream<Double> stream3 = Stream.generate(Math::random).limit(3);
stream3.forEach(System.out::println);
2、Stream 的终止操作
为了方便我们后续的使用,我们先初始化一部分数据:
public class Person {
private String name; // 姓名
private int salary; // 薪资
private int age; // 年龄
private String sex; //性别
private String area; // 地区
public Person() {
}
public Person(String name, int salary, int age, String sex, String area) {
this.name = name;
this.salary = salary;
this.age = age;
this.sex = sex;
this.area = area;
}
}
初始化数据,我们设计一个简单的集合和一个复杂的集合。
public class LambdaTest {
List<Person> personList = new ArrayList<>();
List<Integer> simpleList = Arrays.asList(15, 22, 9, 11, 33, 52, 14);
@Before
public void initData() {
personList.add(new Person("张三", 3000, 23, "男", "太原"));
personList.add(new Person("李四", 7000, 34, "男", "西安"));
personList.add(new Person("王五", 5200, 22, "女", "太原"));
personList.add(new Person("小黑", 1500, 33, "女", "上海"));
personList.add(new Person("狗子", 8000, 44, "女", "北京"));
personList.add(new Person("铁蛋", 6200, 36, "女", "南京"));
}
}
(1)遍历/匹配(foreach/find/match)
将数据流消费掉
@Test
public void foreachTest(){
// 打印集合的元素
simpleList.stream().forEach(System.out::println);
// 其实可以简化操作的
simpleList.forEach(System.out::println);
}
@Test
public void findTest(){
// 找到第一个
Optional<Integer> first = simpleList.stream().findFirst();
// 随便找一个,可以看到findAny()操作,返回的元素是不确定的,
// 对于同一个列表多次调用findAny()有可能会返回不同的值。
// 使用findAny()是为了更高效的性能。如果是数据较少,串行地情况下,一般会返回第一个结果,
// 如果是并行的情况,那就不能确保是第一个。
Optional<Integer> any = simpleList.parallelStream().findAny();
System.out.println("first = " + first.get());
System.out.println("any = " + any.get());
}
@Test
public void matchTest(){
// 判断有没有任意一个人年龄大于35岁
boolean flag = personList.stream().anyMatch(item -> item.getAge() > 35);
System.out.println("flag = " + flag);
// 判断是不是所有人年龄都大于35岁
flag = personList.stream().allMatch(item -> item.getAge() > 35);
System.out.println("flag = " + flag);
}
(2)归集(toList/toSet/toMap)
因为流不存储数据,那么在流中的数据完成处理后,需要将流中的数据重新归集到新的集合里。toList、toSet和toMap比较常用。
下面用一个案例演示toList、toSet和toMap:
@Test
public void collectTest(){
// 判断有没有任意一个人年龄大于35岁
List<Integer> collect = simpleList.stream().collect(Collectors.toList());
System.out.println(collect);
Set<Integer> collectSet = simpleList.stream().collect(Collectors.toSet());
System.out.println(collectSet);
Map<Integer,Integer> collectMap = simpleList.stream().collect(Collectors.toMap(item->item,item->item+1));
System.out.println(collectMap);
}
(3) 统计(count/averaging/sum/max/min)
@Test
public void countTest(){
// 判断有没有任意一个人年龄大于35岁
long count = new Random().ints().limit(50).count();
System.out.println("count = " + count);
OptionalDouble average = new Random().ints().limit(50).average();
average.ifPresent(System.out::println);
int sum = new Random().ints().limit(50).sum();
System.out.println(sum);
}
案例:获取员工工资最高的人
Optional<Person> max = personList.stream().max((p1, p2) -> p1.getSalary() - p2.getSalary());
max.ifPresent(item -> System.out.println(item.getSalary()));
里边的比较器可以改为:Comparator.comparingInt(Person::getSalary)
(4)归约(reduce)
归约,也称缩减,顾名思义,是把一个流缩减成一个值,能实现对集合求和、求乘积和求最值操作。
案例:求
Integer集合的元素之乘积。
@Test
public void reduceTest(){
Integer result = simpleList.stream().reduce(1,(n1, n2) -> n1*n2);
System.out.println(result);
}
(5)接合(joining)
joining可以将 Stream 中的元素用特定的连接符(没有的话,则直接连接)连接成一个字符串。
@Test
public void joiningTest(){
List<String> list = Arrays.asList("A", "B", "C");
String string = list.stream().collect(Collectors.joining("-"));
System.out.println("拼接后的字符串:" + string);
}
(6)分组(partitioningBy/groupingBy)
- 分区:将
stream按条件分为两个Map,比如员工按薪资是否高于 8000 分为两部分。 - 分组:将集合分为多个 Map,比如员工按性别分组。
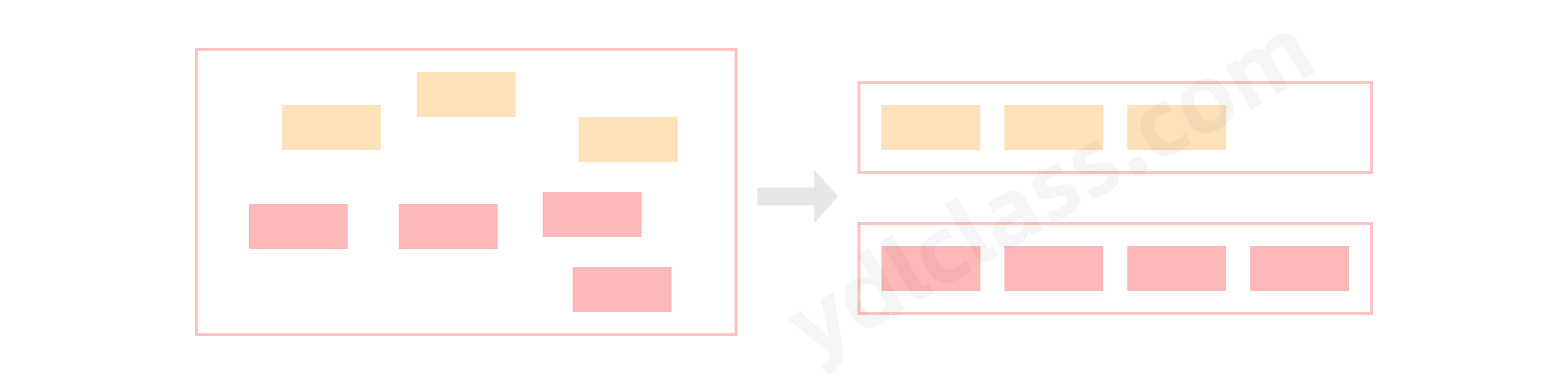
案例:将员工按薪资是否高于 8000 分为两部分;将员工按性别和地区分组
@Test
public void groupingByTest(){
// 将员工按薪资是否高于5000分组
Map<Boolean, List<Person>> part = personList.stream().collect(Collectors.partitioningBy(x -> x.getSalary() > 5000));
// 将员工按性别分组
Map<String, List<Person>> group = personList.stream().collect(Collectors.groupingBy(Person::getSex));
// 将员工先按性别分组,再按地区分组
Map<String, Map<String, List<Person>>> group2 = personList.stream().collect(Collectors.groupingBy(Person::getSex, Collectors.groupingBy(Person::getArea)));
System.out.println("员工按薪资是否大于5000分组情况:" + part);
System.out.println("员工按性别分组情况:" + group);
System.out.println("员工按性别、地区:" + group2);
}
3、Stream 中间操作
(1)筛选(filter)
该操作符需要传入一个 function 函数
筛选出
simpleList集合中大于 17 的元素,并打印出来
simpleList.stream().filter(item -> item > 17).forEach(System.out::println);
筛选员工中工资高于 8000 的人,并形成新的集合。
List<Person> collect = personList.stream().filter(item -> item.getSalary() > 8000).collect(Collectors.toList());
System.out.println("collect = " + collect);
(2)映射(map/flatMap)
映射,可以将一个流的元素按照一定的映射规则映射到另一个流中。分为map和flatMap:
map:接收一个函数作为参数,该函数会被应用到每个元素上,并将其映射成一个新的元素。flatMap:接收一个函数作为参数,将流中的每个值都换成另一个流,然后把所有流连接成一个流。
案例:将员工的薪资全部增加 1000。
personList.stream().map(item -> {
item.setSalary(item.getSalary()+1000);
return item;
}).forEach(System.out::println);
将 simpleList 转化为字符串 list
List<String> collect = simpleList.stream().map(num -> Integer.toString(num))
.collect(Collectors.toList());
(3)排序(sorted)
sorted,中间操作。有两种排序:
- sorted():自然排序,流中元素需实现 Comparable 接口
- sorted(Comparator com):Comparator 排序器自定义排序
案例:将员工按工资由高到低(工资一样则按年龄由大到小)排序
@Test
public void sortTest(){
// 按工资升序排序(自然排序)
List<String> newList = personList.stream().sorted(Comparator.comparing(Person::getSalary)).map(Person::getName)
.collect(Collectors.toList());
// 按工资倒序排序
List<String> newList2 = personList.stream().sorted(Comparator.comparing(Person::getSalary).reversed())
.map(Person::getName).collect(Collectors.toList());
// 先按工资再按年龄升序排序
List<String> newList3 = personList.stream()
.sorted(Comparator.comparing(Person::getSalary).thenComparing(Person::getAge)).map(Person::getName)
.collect(Collectors.toList());
// 先按工资再按年龄自定义排序(降序)
List<String> newList4 = personList.stream().sorted((p1, p2) -> {
if (p1.getSalary() == p2.getSalary()) {
return p2.getAge() - p1.getAge();
} else {
return p2.getSalary() - p1.getSalary();
}
}).map(Person::getName).collect(Collectors.toList());
System.out.println("按工资升序排序:" + newList);
System.out.println("按工资降序排序:" + newList2);
System.out.println("先按工资再按年龄升序排序:" + newList3);
System.out.println("先按工资再按年龄自定义降序排序:" + newList4);
}
(4)peek 操作
peek 的调试作用
@Test
public void peekTest(){
// 在stream中间进行调试,因为stream不支持debug
List<Person> collect = personList.stream().filter(p -> p.getSalary() > 5000)
.peek(System.out::println).collect(Collectors.toList());
// 修改元素的信息,给每个员工涨工资一千
personList.stream().peek(p -> p.setSalary(p.getSalary() + 1000))
.forEach(System.out::println);
}
(5)其他操作
流也可以进行合并、去重、限制、跳过等操作。
@Test
public void otherTest(){
// distinct去掉重复数据
// skip跳过几个数据
// limit限制使用几个数据
simpleList.stream().distinct().skip(2).limit(3).forEach(System.out::println);
}
// 11,11,22,22,11,23,43,55,78
// 去重 11,22,23,43,55,78
// 掉过两个 23,43,55,78
// 使用3个 23,43,55